Optimisation des temps de réponse d'un datawarehouse sous Oracle basée sur la ré-écriture de requêtes en utilisant des vues matérialisées
Date de publication : 13 avril 2009
Par
Nicolas Stefaniuk
Cet article présente, explique et forme à la fonctionnalité de ré-écriture de requêtes d'Oracle, utilisant des vues matérialisées pré-calculant les valeurs.
I. Introduction
II. Résumé
II-A. Qu'est-ce qu'une Vue Matérialisée ?
II-B. Ben qu'est-ce qu'elle a ma requête ?
III. Méthode
III-A. Environnement
III-B. My tailor is rich
III-C. Espace de travail
III-D. Le modèle
III-E. La structure
III-F. Le jeu de données
III-G. Fast and furious
III-H. Les statistiques boudiou !
III-I. Choisir ses VM
III-J. Le compromis des VM
III-K. La technique du bouclier
III-L. Les combinaisons
III-M. Les index sur VM
III-N. Activer / désactiver la ré-écriture
III-O. Pause-café
III-P. Benchmarks
III-P-1. Requêtes basiques
III-P-2. Requêtes d'analyses
III-P-3. Requêtes d'analyse à travers les axes
IV. A venir :
I. Introduction
Le but de cet article est de présenter la ré-écriture de requêtes basée sur l'utilisation de vues matérialisées pré-calculées sous Oracle. Ce genre de techniques s'applique particulièrement sur les datawarehouses où les données changent peu mais où les requêtes aggrégées sont fréquentes et coûteuses. Je souhaite donner au lecteur tous les éléments possibles pour le rendre efficace et autonome sur le sujet, dans la limite de mes propres connaissances. Pour cette raison, cet article fourni aussi des astuces, des logs de mes manipulations et une liste des erreurs qui peuvent survenir, avec leur cause et leur correction que je nommerai troubleshooting, n'ayant pas trouvé de traduction adéquate.
Après un résumé rapide, l'article se compose de 3 parties, chacune comportant des explications, les références aux scripts, les logs, astuces et troubleshooting.
- la création du modèle de test et la première phase d'optimisation,
- la deuxième phase d'optimisation utilisant les Dimensions,
- une liste non exhaustive de pistes à explorer pour aller plus loin sur le sujet ou sur des sujets connexes. Cette partie peut aussi rediriger vers d'autres articles complémentaires.
Le point absolument essentiel de cet article est que je le livre tel quel, sans aucune garantie d'aucune sorte. Je ne m'engage à aucun résultat ni au fait que je ne dise pas des énormités parfois (bien qu'en principe je préfère ne pas m'étendre sur un sujet plutôt que de raconter doctement une sottise). J'ai essayé d'écrire un guide de qualité, compréhensible, pas complet mais contenant tout ce qu'il faut pour pouvoir appliquer les principes décrits ici sur des cas réels, mais ce n'est qu'un article écrit sur mon temps libre avec ma fille sur les genoux. Il n'a donc pas la qualité d'une production professionnelle réalisée par un expert. D'ailleurs si un lecteur a des corrections / améliorations / conseils / idées à apporter je lui en serais reconnaissant.
II. Résumé
Les temps de réponses sont le premier problème d'un datawarehouse, et les solutions pour les réduire se trouvent à de nombreux niveaux :
- limiter le besoin,
- revoir la modélisation,
- optimiser la base (tuning).
L'optimisation de la base englobe toutes les actions permettant d'améliorer les performances d'une manière transparente pour la modélisation et l'utilisateur (excepté le gain de performances bien entendu). On peut la séparer en 2 grandes parties :
- l'optimisation bas niveau & globale : cette optimisation demande de solides compétences en administration (SGBDR et OS) et les droits pour le faire. Elle consiste à faire varier les nombreux paramètres de la base pour diminuer les pertes de charge : taille des blocs, SGA, organisation des disques, etc. Cette partie là est à réserver aux DBA. Le risque de cette optimisation est quelle impactera souvent toute la base, ce qui peut être problèmatique si la modification d'un paramètre bénéficie à une application mais en pénalise une autre. Evidemment de versions en versions, Oracle améliore sa souplesse et permet d'adapter de plus en plus de paramètres à chaque besoin.
- l'optimisation ciblée : cette optimisation peut se mener en collaboration entre l'architecte de l'application et le DBA. Elle consiste à créer des objets qui permettent à Oracle d'améliorer ses temps de réponse : index, vues et vues matérialisées. L'objectif est que ces objets améliorent les temps de réponse mais n'impactent pas l'aspect fonctionnel de l'application (même si parfois on pas le choix). Par exemple si vous dites à votre utilisateur "Je te fais un index, ça ira beaucoup plus vite, mais 5 à 10% de tes données risquent d'être fausses", il risque d'être difficile à convaincre. Heureusement ce genre de cas n'arrivent pas, et le seul compromis à faire avec l'utilisateur sera sur le délai de mise à jour / mise à disposition des données.
C'est l'optimisation locale qui nous intéresse ici, et plus particulièrement le fait de pré-calculer des informations pour éviter de faire le même travail plusieurs fois. Dans cette définition, on peut bien évidemment placer les Index, qui permettent d'indexer les données pour pouvoir les retrouver plus vite et plus efficacement, mais ce n'est encore une fois pas le sujet de l'article. L'élement qui nous intéresse ici c'est la ré-écriture de requêtes basée sur l'utilisation de vues matérialisées pré-calculées.
II-A. Qu'est-ce qu'une Vue Matérialisée ?
Une Vue Matérialisée (VM) est une table d'un type particulier contenant le résultat d'une requête. Sa caractéristique est donc que son contenu représente le résultat à l'instant de sa création de la requête sur laquelle elle est basée. Contrairement à une vue, une VM contient donc des données, ce qui implique que :
- elle occupe de l'espace disque,
- si on la drop on peut perdre de l'information (bien que son but ne soit absolument pas de jouer un rôle de sauvegarde des données à un instant t. Utilisez des tables pour ça),
- les données sont calculées à un instant t, elles ne sont donc mises à jour que si vous le specifiez,
- si la VM est construite en read-only, les données ne sont pas modifiables par des commandes DML comme INSERT/DELETE/UPDATE.
La construction d'une VM accepte les mêmes paramètres qu'une table (à peut-être quelques exceptions que je ne connais pas) et finalement on peut se dire qu'il n'y a pas de grande différence à utiliser une VM ou à alimenter une table aggrégée à l'aide d'un script SQL ou d'un ETL (à part les possibilités avancées dont on ne parlera que dans la 3e partie telles que le refresh on commit).
C'est vrai sauf si on souhaite utiliser la ré-écriture de requête.
II-B. Ben qu'est-ce qu'elle a ma requête ?
Sous certaines conditions, Oracle peut décider de ré-écrire une requête pour améliorer les performances, et ceci de manière transparente pour l'utilisateur. Oracle va estimer le coût de la requête qui lui est soumise, puis la ré-écrire en utilisant un algorithme et les éléments à sa disposition. Puis il va comparer le coût estimé de cette requête ré-écrite avec celle d'origine. Si le coût est moindre, il utilisera la requête ré-écrite. Finalement on retrouve là le comportement des index, où Oracle choisi d'utiliser un index ou un autre en fonction de ce qu'il estime le plus performant. Qui ne s'est jamais exclamé "Mais pourquoi il fait un full scan cet abruti ! Y a un index !" ? Les voies du CBO (Cost Based Optimizer) sont impénétrables...
De la même manière que pour bien utiliser les index Oracle a besoin de statistiques à jour, un certain nombre de conditions sont nécessaires pour utiliser la ré-écriture de requêtes et tous les problèmes de performance ne pourront pas être résolus de cette manière. De plus, la ré-écriture de requête nécessite qu'Oracle comprenne la requête d'origine, ce qui implique qu'elle ne soit pas trop compliquée.
III. Méthode
III-A. Environnement
La version d'Oracle utilisée pour cet exemple est une 10.2.0.1 avec options partitionning et OLAP sur une machine virtuelle de 600 Mo de RAM et 1 seul CPU. Si vous installez vous même votre base il me semble que les options sont à choisir à l'installation, je n'ai pas vu l'intérêt de monter une documentation d'installation. Attention je pense que ces options n'existent pas sur une XE. Je ne peux rien garantir sur le fonctionnement de cet article pour des versions antérieures.
III-B. My tailor is rich
Les scripts et la structure des tables sont en Anglais, pas parce que j'aime particulièrement l'Anglais ni pour rendre le script portable mais parce que les commandes sont en Anglais (CREATE, ALTER, etc.) et que je n'aime pas avoir plusieurs langues mélangées dans mes scripts. Les messages oracle des logs et troubleshooting sont en Français par contre, pour donner la possibilité de faire une recherche sur les messages dans l'article.
III-C. Espace de travail
Pour commencer, nous allons initialiser notre espace de travail. La base s'appelle orcl.
Tout l'article sera basé sur un utilisateur nommé DEMO_USR. Tous les scripts seront volontairement préfixés avec cet utilisateur. Pour les jouer sur un autre utilisateur il faut donc procéder à un rechercher / remplacer dans tous les scripts / exemples. J'ai préféré faire ce choix car cet article nécessite de travailler énormément sur l'utilisateur (gestion des droits, trace des sessions, etc.), donc il aurait de toute façon fallu adapter le nom de l'utilisateur à un moment ou à un autre.
La première chose à faire est bien sûr de créer l'utilisateur. Soit vous créez un utilisateur qui s'appelle DEMO_USR en utilisant le script
001 - Create_User_DEMO_USR.sql, soit vous vous débrouillez... Dans ce cas, n'oubliez pas de bien attribuer les droits. Je n'aime pas donner des roles sans savoir pourquoi (surtout le role DBA) donc à chaque étape j'ai essayé de ne donner que les droits minimum pour l'étape. De plus je ne me suis pas encombré de considérations sur le tablespace par défaut, les quotas, etc. Si vous n'avez pas les droits suffisants pour gérer ce genre de choses, adressez-vous à votre DBA pour initialiser l'espace de travail.
Pour créer l'utilisateur, connectez-vous donc avec un utilisateur qui a assez de droits et lancez le script suivant :
001 - Create_User_DEMO_USR.sql. Une fois l'utilisateur DEMO_USR créé, ouvrez une session avec lui avec DEMO_USR comme mot de passe.
Si votre DBA est du genre à se faire désirer, demandez-lui d'exécuter ce script aussi :
005 - Grant_BI_Rights_DEMO_USR.sql, ça sera du temps gagné pour plus tard (qui sera utilisé à ce point de l'article)
III-D. Le modèle
Pour notre exemple nous allons nous baser sur un modèle en flocon constitué de:
- 1 table de faits des ventes (F_SALE) contenant:
- 2 faits : montant de la vente (SAL_AMOUNT) et montant de la remise (SAL_DISCOUNT_AMOUNT)
- 1 attribut : date et heure de la vente (SAL_DATETIME)
- 4 dimensions : date de la vente (SAL_DATE), produit vendu (SAL_PRODUCT), vendeur (SAL_VENDOR) et client (SAL_CUSTOMER)
- 11 tables de dimensions organisées en 4 axes d'analyse:
- Axe temps : table D_CALENDAR, dénormalisée
- Axe produit : tables D_PRODUCT, D_PRODUCT_SUB_FAMILY et D_PRODUCT_FAMILY normalisées
- Axe vendeur : tables D_VENDOR, D_AGENCY, D_REGION et D_COUNTRY normalisées
- Axe client : tables D_CUSTOMER, D_CUSTOMER_SUB_GROUP et D_CUSTOMER_GROUP normalisées
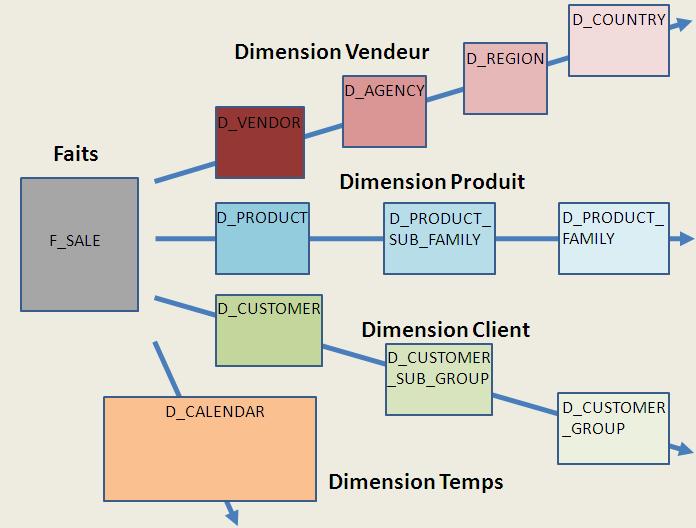
Le modèle
Note : les notions de dimensions et de faits sont connues de tous, la notion d'attribut peut-être moins. La définition d'un attribut utilisée ici est : information n'étant ni un fait, ni une dimension, et par conséquent n'étant pas destinée à être utilisée dans l'analyse. Par exemple ici l'attribut est "la date et l'heure de la vente". Alors que la date est un élément de la dimension Temps, l'heure n'a aucune importance pour l'analyse. C'est ainsi qu'est conçu le modèle. Si l'heure de vente était importante pour mener des analyses par exemple sur les meilleures heures de vente par périodes, l'heure aurait été modélisée comme une dimension, avec des clés de regroupement (8h, 9h, 10h, etc. puis un niveau au dessus MATIN, APRES-MIDI etc.). Cela implique aussi que si les utilisateurs souhaitent utiliser l'heure dans leurs analyses, ils sortent du périmètre défini, et donc il est très probable que l'optimisation que nous avons prévue devienne inefficace.
Les tables et leurs champs sont les suivants:
Faits
F_SALE
| SAL_ID |
| SAL_AMOUNT |
| SAL_DISCOUNT_AMOUNT |
| SAL_DATETIME |
| SAL_DATE |
| SAL_PRODUCT |
| SAL_VENDOR |
| SAL_CUSTOMER |
Dimension Temps
D_CALENDAR
| CAL_DATE |
| CAL_DAY_OF_WEEK |
| CAL_YEARMONTH |
| CAL_MONTH_OF_YEAR |
| CAL_MONTH_DESC |
| CAL_YEAR |
| CAL_YEAR_DESC |
Dimension Produit
D_PRODUCT
| PRO_ID |
| PRO_SUB_FAMILY |
| PRO_DESC |
D_PRODUCT_SUB_FAMILY
| PSF_ID |
| PSF_FAMILY |
| PSF_DESC |
D_PRODUCT_FAMILY
Dimension Vendeur
D_VENDOR
| VDR_ID |
| VDR_AGENCY |
| VDR_NAME |
D_AGENCY
| AGC_ID |
| AGC_REGION |
| AGC_NAME |
D_REGION
| REG_ID |
| REG_COUNTRY |
| REG_NAME |
D_COUNTRY
Dimension Client
D_CUSTOMER
| CUS_ID |
| CUS_SUB_GROUP |
| CUS_NAME |
D_CUSTOMER_SUB_GROUP
| CSB_ID |
| CSB_GROUP |
| CSB_DESC |
D_CUSTOMER_GROUP
Ce modèle permet de valider les cas suivants :
- une dimension à faible sélectivité au niveau le plus fin, basée sur plusieurs tables norméalisées hierarchisées (axe Vendeur). Cette dimension est le cas le plus classique.
- une dimension basée sur une table dénormalisée (axe temps). Cette dimension permettra de montrer comment appliquer les dimensions sur des tables dénormalisées.
- une dimension à forte sélectivité au niveau le plus fin, basée sur plusieurs tables norméalisées hierarchisées (axe Client). Cette dimension sera très intéressante au moment d'utiliser des dimensions.
- une dimension à très faible sélectivité au niveau le plus fin, basée sur plusieurs tables norméalisées hierarchisées (axe Produit). Cette dimension est juste là pour faire un niveau d'analyse supplémentaire.
III-E. La structure
Pour créer la structure de base de données il faut lancer le script
002 - Create_Database_Structure.sql. Note: les erreurs lors des DROP sont normales à la première exécution du script.
Des options avancées d'organisation telles que le partitionnement, la compression, l'utilisation d'index particuliers (bitmap), l'option nologging ou l'organisation en index des tables de dimensions ont été volontairement ignorées pour cet article, vu que ça n'apporte pas grand chose au sujet de la ré-écriture de requêtes. Pour une application sur cas réel, il faudrait bien entendu en tenir compte.
III-F. Le jeu de données
Nous allons maintenant alimenter nos tables de manière automatisée pour 2 raisons :
- nous avons besoin d'un volume de données suffisant pour qu'Oracle juge nécessaire la ré-écriture de requêtes, et un tel volume serait compliqué à générer de manière non automatisée (sauf avec un dump de tables ou un énorme fichier d'insert, éventuellement).
- pour nos tests il est préférable d'avoir un jeu de données connu, et donc généré de manière maîtrisée plutôt qu'aléatoire.
1 000 000 de lignes devraient suffire à la démonstration. Pour générer ces 1 000 000 lignes, nous allons utiliser la table ALL_OBJECTS qui contient environ 40 000 lignes. En faisant un produit cartésien avec elle même, on peut monter jusqu'à 1 600 000 000 lignes (mais nous allons la limiter à 1 000 000). Un code PL/SQL est aussi disponible mais il est plus lent à générer les lignes.
Notez que nous allons d'abord alimenter la table de fait, puis nous allons alimenter les tables de dimension à partir des données de la table de fait. Enfin nous activerons les clés étrangères. Ceci permet de garantir la cohérence des données crées automatiquement.
Exécutez le script
003 - Create_Source_Data.sql. Ce script s'occupe de désactiver les contraintes et d'effacer les tables (au cas où vous l'ayez déjà lancé) puis génére 1 000 000 lignes dans la table de fait. Ensuite il peuple les tables de dimensions à partir des données de la table de fait. Il dure moins de 10mn sur mon environnement.
En exécutant le script
004 - Stats on Source Data.sql, vous obtenez des statistiques sur les données de notre modèle, qui vont nous être bien utiles pour valider le comportement de nos tables aggrégées. De plus il est temps de faire quelques requêtes pour valider qu'il y a un problème de performances.
Les données doivent ressembler à ça:
- Nombre de lignes : 1000000
- Montant total : 49500000
- Montant total des remises : 12375000
- Montant total net : 37125000
- Nombre de jours de vente : 3175
- Nombre de produits : 10
- Nombre de vendeurs : 7
- Nombre de clients : 20000
- Date de la 1ere vente : 01/01/00
- Date de la derniere vente : 09/09/08
- Somme des ventes pour le 01/01/2000 : 14955
- Somme des ventes pour le Produit 1 : 4950000
- Somme des ventes pour le Vendeur 1 : 1050000
- Somme des ventes pour le client 1 : 50
III-G. Fast and furious
Si les durées des requêtes sont déjà assez longues sur cet exemple on peut imaginer les dérives avec 100 fois plus de lignes et des lignes 100 fois plus lourdes. Nous allons donc nous attacher à essayer de réduire les délais des requêtes en utilisant la ré-écriture de requête. Ce qui est intéressant c'est que ce modèle pourrait servir à démontrer les bénéfices d'autres techniques, que j'évoquerai à la fin de cet article.
Comme expliqué auparavant, la ré-écriture de requête fonctionne de la façon suivante:
- Oracle parse la requête qui lui est soumise et en estime le coût,
- il utilise les éléments à sa disposition pour ré-écrire la requête et estime le coût de cette nouvelle requête. Ce qui est important c'est de comprendre qu'on a la possibilité d'orienter ses choix en créant plus ou moins d'éléments dont il peut se servir mais qu'on ne maîtrise absolument pas sa ré-écriture et que ce qu'il décide de faire peut nous sembler aberrant (comme cela arrive parfois avec le CBO et le choix des index),
- il compare les coûts des 2 requêtes et choisi la moins coûteuse.
Notons que cela implique que pour toutes les requêtes il va donc faire une ré-écriture et 2 parsing (au moins, je ne suis pas sûr qu'il ne tente pas plusieurs ré-écritures possibles), ce qui peut s'avérer plus coûteux en temps que la requête elle même. La ré-écriture n'a vraiment de l'intérêt que pour les requêtes coûteuses. Oracle utilise peut-être des critères non documentés pour décider de tenter de ré-écrire ou non une requête, du genre s'il sait que les tables en jeu contiennent peu de lignes. Ceci implique donc que pour faire de la ré-écriture de requêtes il faut l'avoir choisi, et chez Oracle ça se traduit par le fait d'avoir les droits.
Nous allons faire un 2e lot d'attribution de droits. Vous avez besoin de droits pour créer les objets suivants:
- MATERIALIZED VIEW
- DIMENSION
Il vous faut les droits suivants pour pouvoir procéder à de la ré-écriture de requêtes:
- QUERY REWRITE, suffisant pour cet article,
- GLOBAL QUERY REWRITE, normalement inutile pour cet article puisque ce droit permet juste de faire de la ré-écriture de requête à travers les schémas mais selon l'architecture choisie il peut être nécessaire...
III-H. Les statistiques boudiou !
Comme dit auparavant, il est important de respecter un certain nombre de conditions pour utiliser correctement la ré-écriture de requêtes. Une de ces conditions est le calcul des statistiques. Les statistiques doivent être à jour sur vos objets, et ce encore plus que d'habitude car c'est grace aux statistiques qu'Oracle va estimer si la ré-écriture est intéressante par rapport à la requête initiale. Pour calculer les statistiques, utilisez le package DBMS_STATS.
Par exemple pour calculer les statistiques sur la table DEMO_USR.F_SALE, il faut lancer la commande suivante :
exec DBMS_STATS.GATHER_TABLE_STATS('DEMO_USR', 'F_SALE');
|
Il existe de nombreuses options que je ne détaillerai pas, parlez-en avec votre DBA.
III-I. Choisir ses VM
Il faut bien comprendre, comme dit au début du document, que la ré-écriture de requêtes basée sur des VM est une forme de tuning, et qu'elle doit être adaptée à l'évolution du modèle, des données et des besoins. Comme les index, de nouvelles VM peuvent devenir nécessaires à posteriori, alors que d'autres deviennent obsolètes. Un exemple classique est un changement de clé fonctionnelle dans le modèle : hier la clé fonctionnelle unique était obtenue par nom+prénom+agence et aujourd'hui on a introduit un nouveau champ qui contient un identifiant unique, disons matricule. Dans ce cas tous les index seront sûrement à reprendre, et les VM aussi.
Il n'y a donc pas de règle évidente pour choisir les VM à créer, et il faudra des analyses et des tests pour déterminer ce qu'il est judicieux de créer ou pas. On peut toutefois poser les 3 principes suivants :
- la ré-écriture de requêtes passe avant tout par des compromis,
- si possible il est bon de poser au moins un bouclier,
- s'il y a peu de dimensions, il peut-être avantageux de calculer toutes les combinaisons plutôt qu'essayer d'en sélectionner.
III-J. Le compromis des VM
Le compromis avec lequel il faut composer se situe entre [espace disque utilisé par les VM, temps de calcul des VM ] et [ressources économisées lors des requêtes, fréquence d'utilisation des VM par les requêtes]. Ceci implique qu'une VM qui est longue à calculer et qui occupe de l'espace et qui n'est que très rarement utilisée n'est pas intéressante à utiliser. Par contre une VM qui permet de répondre à 50% des demandes et qui les améliore grandement vaudra le coup d'être calculée, même si elle demande beaucoup de temps de calcul et utilise de l'espace disque.
III-K. La technique du bouclier
Le bouclier consiste en une VM peu aggrégée, calculée seulement sur la table de fait (donc sans lier les tables de dimension) qui contient le niveau le plus fin de toutes les dimensions et les indicateurs aggrégés. Ainsi cela permet d'assurer les points suivants:
- toute requête d'analyse (dimensions + faits mais PAS d'attributs) passera au minimum par cette table, ce qui permet d'assurer un minimum de performance dans l'analyse, même avec une seule VM,
- dans le cas où la table de fait contient de nombreux (ou lourds) attributs, le bouclier sera une VM beaucoup plus rapide à scanner même en full scan car pour ramener les mêmes informations il y aura beaucoup moins de blocs à aller lire,
- dans le cas où la table de fait contient un faible nombre de dimensions avec de faibles sélectivités, le bouclier sera une VM assez légère et d'autres VM ne seront peut-être même pas nécessaires.
Encore une fois, le principe du bouclier c'est de dire : j'ai tout ce dont j'ai besoin pour faire toutes mes analyses. Si j'ai besoin d'un élément qui n'est pas dans mon bouclier (un attribut), alors je devrais aller attaquer ma table de faits mais c'est normal car je sors du cadre de l'analyse dimensionnelle. Le bouclier protège donc la table de faits en prenant sur lui toutes les requêtes qui voudraient l'attaquer (toujours en considérant que les requêtes restent sur le périmètre d'analyse).
Dans notre modèle le bouclier est donc constitué des 4 dimensions, des 2 indicateurs sommés et d'un compteur du nombre de lignes:
- SAL_DATE
- SAL_PRODUCT
- SAL_VENDOR
- SAL_CUSTOMER
- sum(SAL_AMOUNT)
- sum(SAL_DISCOUNT_AMOUNT)
- count(*)
Note: SAL_DATETIME est un attribut et est donc exclu du périmètre d'analyse et donc du bouclier.
On remarquera que l'utilisation d'un bouclier est presque inutile si toutes les dimensions forment une clé unique ou, du moins, très discriminante, car dans ce cas le seul intérêt du bouclier sera d'avoir une VM sans les attributs de la table de faits (il y aura donc moins de données inutiles pour l'analyse à ramener dans les blocs). Par contre le bouclier garde de l'intérêt même s'il n'y a aucun attribut, car dans ce cas le bouclier permet quand même de réduire le nombre de lignes, réduction qui peut-être très importante.
III-L. Les combinaisons
A partir de notre bouclier, nous allons pouvoir construire toutes les VM dont on a besoin pour répondre à nos besoins. Pour l'illustration de cet article, et comme il n'y a que 4 dimensions, nous allons faire toutes les possibilités. Dans la réalité il faudrait analyser les VM les plus pertinentes.
Nous allons créer n VM sur m niveaux différents. m est égal au nombre de dimensions du bouclier, cad le nombre MAXIMAL de dimensions de notre modèle, ici m = 4, n vaut donc 16.
Illustration :
Au niveau 4 nous avons notre bouclier à 4 dimensions:
| Niveau |
VM |
Dimensions |
| 4 |
4-1 |
SAL_DATE - SAL_PRODUCT - SAL_VENDOR - SAL_CUSTOMER |
Il n'y a qu'une seule combinaison avec 4 dimensions, on a donc une seule VM pour le niveau 4, qu'on appelera VM_LVL4_001.
Le niveau en dessous est constitué de 3 dimensions. On prends donc 3 dimensions sur les 4 disponibles, ce qui donne C(3,4) combinaisons possibles. Pour rappel C(3,4) = 4!/(3! * (4-3)!) = 24/(6 * 1) = 4.
| Niveau |
VM |
Dimensions |
| 4 |
4-1 |
SAL_DATE - SAL_PRODUCT - SAL_VENDOR - SAL_CUSTOMER |
| 3 |
3-1 |
SAL_DATE - SAL_PRODUCT - SAL_VENDOR - |
| 3 |
3-2 |
SAL_DATE - SAL_PRODUCT - - SAL_CUSTOMER |
| 3 |
3-3 |
SAL_DATE - - SAL_VENDOR - SAL_CUSTOMER |
| 3 |
3-4 |
- SAL_PRODUCT - SAL_VENDOR - SAL_CUSTOMER |
Ce niveau 3 devrait nous permettre de répondre à toutes les analyses qui nécessitent 3 axes d'analyse.
Le niveau en dessous est constitué de 2 dimensions. On prends donc 2 dimensions sur les 4 disponibles, ce qui donne C(2,4) combinaisons possibles. Pour rappel C(2,4) = 4!/(2! * (4-2)!) = 24/(2 * 2) = 6.
| Niveau |
VM |
Dimensions |
| 4 |
4-1 |
SAL_DATE - SAL_PRODUCT - SAL_VENDOR - SAL_CUSTOMER |
| 3 |
3-1 |
SAL_DATE - SAL_PRODUCT - SAL_VENDOR - |
| 3 |
3-2 |
SAL_DATE - SAL_PRODUCT - - SAL_CUSTOMER |
| 3 |
3-3 |
SAL_DATE - - SAL_VENDOR - SAL_CUSTOMER |
| 3 |
3-4 |
- SAL_PRODUCT - SAL_VENDOR - SAL_CUSTOMER |
| 2 |
2-1 |
SAL_DATE - SAL_PRODUCT - - |
| 2 |
2-2 |
SAL_DATE - - SAL_VENDOR - |
| 2 |
2-3 |
- SAL_PRODUCT - SAL_VENDOR - |
| 2 |
2-4 |
SAL_DATE - - - SAL_CUSTOMER |
| 2 |
2-5 |
- SAL_PRODUCT - - SAL_CUSTOMER |
| 2 |
2-6 |
- - SAL_VENDOR - SAL_CUSTOMER |
Ce niveau 2 devrait nous permettre de répondre à toutes les analyses qui nécessitent 2 axes d'analyse.
Le niveau en dessous est constitué de 1 dimension. On prends donc 1 dimension sur les 4 disponibles, ce qui donne C(1,4) combinaisons possibles. Pour rappel C(1,4) = 4!/(1! * (4-1)!) = 24/(1 * 6) = 4.
| Niveau |
VM |
Dimensions |
| 4 |
4-1 |
SAL_DATE - SAL_PRODUCT - SAL_VENDOR - SAL_CUSTOMER |
| 3 |
3-1 |
SAL_DATE - SAL_PRODUCT - SAL_VENDOR - |
| 3 |
3-2 |
SAL_DATE - SAL_PRODUCT - - SAL_CUSTOMER |
| 3 |
3-3 |
SAL_DATE - - SAL_VENDOR - SAL_CUSTOMER |
| 3 |
3-4 |
- SAL_PRODUCT - SAL_VENDOR - SAL_CUSTOMER |
| 2 |
2-1 |
SAL_DATE - SAL_PRODUCT - - |
| 2 |
2-2 |
SAL_DATE - - SAL_VENDOR - |
| 2 |
2-3 |
- SAL_PRODUCT - SAL_VENDOR - |
| 2 |
2-4 |
SAL_DATE - - - SAL_CUSTOMER |
| 2 |
2-5 |
- SAL_PRODUCT - - SAL_CUSTOMER |
| 2 |
2-6 |
- - SAL_VENDOR - SAL_CUSTOMER |
| 1 |
1-1 |
SAL_DATE - - - |
| 1 |
1-2 |
- SAL_PRODUCT - - |
| 1 |
1-3 |
- - SAL_VENDOR - |
| 1 |
1-4 |
- - - SAL_CUSTOMER |
Ce niveau 1 devrait nous permettre de répondre à toutes les analyses qui nécessitent 1 axe d'analyse.
Le dernier niveau est constitué de 0 dimension. On prends donc 0 dimension sur les 4 disponibles, ce qui donne C(0,4) combinaisons possibles. Pour rappel C(0,4) = 4!/(0! * (4-0)!) = 24/(1 * 24) = 1.
| Niveau |
VM |
Dimensions |
| 4 |
4-1 |
SAL_DATE - SAL_PRODUCT - SAL_VENDOR - SAL_CUSTOMER |
| 3 |
3-1 |
SAL_DATE - SAL_PRODUCT - SAL_VENDOR - |
| 3 |
3-2 |
SAL_DATE - SAL_PRODUCT - - SAL_CUSTOMER |
| 3 |
3-3 |
SAL_DATE - - SAL_VENDOR - SAL_CUSTOMER |
| 3 |
3-4 |
- SAL_PRODUCT - SAL_VENDOR - SAL_CUSTOMER |
| 2 |
2-1 |
SAL_DATE - SAL_PRODUCT - - |
| 2 |
2-2 |
SAL_DATE - - SAL_VENDOR - |
| 2 |
2-3 |
- SAL_PRODUCT - SAL_VENDOR - |
| 2 |
2-4 |
SAL_DATE - - - SAL_CUSTOMER |
| 2 |
2-5 |
- SAL_PRODUCT - - SAL_CUSTOMER |
| 2 |
2-6 |
- - SAL_VENDOR - SAL_CUSTOMER |
| 1 |
1-1 |
SAL_DATE - - - |
| 1 |
1-2 |
- SAL_PRODUCT - - |
| 1 |
1-3 |
- - SAL_VENDOR - |
| 1 |
1-4 |
- - - SAL_CUSTOMER |
| 0 |
0-1 |
- - - |
Ce niveau 0 devrait nous permettre de répondre à toutes les analyses qui nécessitent 0 axe d'analyse. Autant dire qu'il est plus là pour la cohérence de l'ensemble que pour l'utilité lors d'analyses.
Nous obtenons donc 16 tables, un résultat que nous pouvions prévoir ainsi : Sommei=0..1( C(i,4) ) = C(0,4) + C(1,4) + C(2,4) + C(3,4) + C(4,4) = 1 + 4 + 6 + 4 + 1 = 16.
Imaginons que nous décidions de rajouter une 5e dimension, la notion de solde / pas solde par exemple. Nous n'aurions pas besoin de changer nos 16 tables, nous aurions juste à en rajouter de nouvelles. Nous créerions la table VM_LVL5_001 basée sur les 5 dimensions, qui deviendrait notre nouveau bouclier, et l'ancien bouclier VM_LVL4_001 deviendrait juste la première des 5 VM du niveau 4. Car au niveau 4 on aurait C(4,5) = 5!/(4! * (5-4)!) = 120 / (24 * 1) = 5 VM différentes. Au final nous aurions S(i=0..1) C(i,5) = C(0,5) + C(1,5) + C(2,5) + C(3,5) + C(4,5) + C(5,5) = 1 + 5 + 10 + 10 + 5 + 1 = 32. Soit 16 tables de plus, ce qui double le nombre de tables.
On remarquera que le nombre total de tables = 2^(le nombre max de dimensions) ce qui était prévisible sachant que le nombre de sous-ensembles d'un ensemble à n éléments est 2^n. Ceci implique qu'à chaque dimension supplémentaire on double le nombre de tables si on veut couvrir toutes les possibilités.
III-M. Les index sur VM
Le principe d'un index est d'accéder rapidement à de l'information. Si consulter l'index PUIS aller chercher l'information à l'endroit indiqué par l'index est plus long que chercher directement l'information en parcourant toute les données, l'index est inutile.
Imaginons la VM bouclier LVL4-001, elle contient les 4 dimensions : SAL_DATE - SAL_PRODUCT - SAL_VENDOR - SAL_CUSTOMER
Je pourrais me dire : tiens, je vais faire un index sur SAL_CUSTOMER et SAL_VENDOR. Comme ça si j'ai une analyse à faire sur SAL_CUSTOMER et SAL_VENDOR, la requête passe par l'index, c'est plus rapide. Erreur ! Car si je cherche à faire une analyse sur SAL_CUSTOMER et SAL_VENDOR, c'est en fait la VM LVL2-006 qui sera utilisée et l'index sur LVL4-001 sera inutile. Evidemment il se trouvera bien quelqu'un pour me sortir un contre-exemple, par exemple le fait qu'Oracle préfère parfois passer par une VM d'un périmètre plus large plutôt qu'utiliser la VM qui a exactement le périmètre qui va bien, sûrement parce que la VM d'un périmètre plus large est déjà montée en cache.
Cas particulier : si je veux analyser mes données sur SAL_DATE, SAL_PRODUCT, SAL_VENDOR en filtrant sur SAL_CUSTOMER = 'x'. Dans ce cas effectivement, et parce que SAL_CUSTOMER a une grosse sélectivité, un index sur la VM peut être intéressant. Cette possibilité n'est donc pas à écarter sans analyse, mais ce n'est pas la première chose sur laquelle travailler.
III-N. Activer / désactiver la ré-écriture
La ré-écriture de requête peut être activée / désactivée à volonté par une modification de la session:
ALTER SESSION SET QUERY_REWRITE_ENABLED = 'true';
ALTER SESSION SET QUERY_REWRITE_ENABLED = 'false';
|
Le niveau d'intégrité que respecte Oracle lors de la ré-écriture de requête peut lui aussi être réglé:
- Enforced (valeur par défaut) : assez contraignant car Oracle exige que l'intégrité entre les VM et les tables ré-écrites soient assurée.
- Trusted (valeur conseillée) : c'est la valeur avec laquelle nous allons travailler sur cet article. Oracle nous fait confiance pour l'intégrité des données.
- Stale tolerated : Oracle procède à de la ré-écriture même s'il sait que les données des VM ne sont pas cohérentes avec les tables ré-écrites. Je n'aime pas trop cette option dans un datawarehouse correctement monté. Par contre pour un pseudo datawarehouse constitué de VM calculée à partir des tables de la base opérationnelle, pourquoi pas.
|
ALTER SESSION set query_rewrite_integrity = ENFORCED;
ALTER SESSION set query_rewrite_integrity = TRUSTED;
ALTER SESSION set query_rewrite_integrity = STALE_TOLERATED;
|
III-O. Pause-café
Ce script :
- drop tout ce qu'il va re-créer,
- calcule toutes les statistiques, pour être sûr que les statistiques soient calculées sur les tables de notre modèle,
- créé les VM,
- calcule les statistiques sur les VM.
III-P. Benchmarks
III-P-1. Requêtes basiques
Nous allons lancer les mêmes requêtes que celles qui ont servi à créer les VM une fois en désactivant la ré-écriture puis en l'activant et afficher le plan d'exécution. La requête non ré-écrite sera basée sur la table de faits alors que la requête ré-écrite sera basée sur la VM qui convient le mieux. Le but est seulement de tester le fonctionnement de nos requêtes.
Le principe est simple:
- activer l'autotrace, qui permet de voir le plan d'exécution de la requête et ses coûts:
- positionner le mode de ré-écriture de requête à TRUSTED:
|
ALTER SESSION set query_rewrite_integrity = TRUSTED;
|
- désactiver la ré-écriture de requête:
ALTER SESSION SET QUERY_REWRITE_ENABLED = 'false';
|
- exécuter la requête:
|
SELECT <dimensions>, <faits aggrégés> FROM "DEMO_USR"."F_SALE" GROUP BY <dimensions>
|
- noter son plan d'éxécution, son coût et sa durée réelle (rappel : le plan d'exécution ne s'affiche que si vous avez activé l'autotrace):
- activer la ré-écriture de requête:
ALTER SESSION SET QUERY_REWRITE_ENABLED = 'true';
|
- ré-exécuter la requête
- noter son nouveau plan d'éxécution, son coût et sa durée:
- Remarquer que l'utilisation de la Vue Matérialisée diminue grandement les temps d'exécution (ici de 8.93s à 0.90s) et le coût (de 6426 à 104), et ça particulièrement si on utilise peu de dimensions, mais qu'on ne peut pas écrire une fonction prédictive, qui permettrait d'estimer le gain en délai en fonction de la diminution d'espace disque entre la table source et la VM. Par exemple on a divisé les temps de "seulement" 10 en ayant divisé:
- le coût par 61 (de 6426 à 104),
- le nombre d'octets par 139 (de 62464 à 448),
- le nombre de blocs par 139 (de 7808 à 56).
Notez que le cache risque de venir fausser les résultats, dans ce cas il faut utiliser la commande suivante:
|
alter system flush buffer_cache;
|
III-P-2. Requêtes d'analyses
Nous allons lancer des requêtes plus compliquées, intégrant notamment des clauses where pour valider que les VM permettent de répondre aux besoins d'analyse.
On peut constater 4 cas :
- la ré-écriture a lieu et est efficace. C'est le cas d'une requête qui aggrège sur SAL_VENDOR en filtrant sur SAL_DATE, car sans ré-écriture la requête exécute un FULL SCAN de la table F_SALE.
- la ré-écriture a lieu mais est peu efficace. C'est le cas d'une requête qui filtre sur SAL_CUSTOMER car l'index IDX_SALE_ALL_DIM permet d'accélérer l'accès aux données de la table F_SALE.
- la ré-écriture n'a pas lieu car pas assez efficace (cas qui sera démontré plus loin dans l'article).
- la ré-écriture n'a pas lieu car l'information ne peut être obtenue dans les VM : des attributs sont utilisés ou un calcul non présent dans les VM est demandé (une moyenne par exemple alors que la fonction d'aggrégation utilisée dns les VM de notre modèle est la somme).
Le but n'est pas de montrer que les VM sont inutiles, mais plutôt de confirmer que le périmètre d'analyse doit être bien défini pour éviter les surprises.
III-P-3. Requêtes d'analyse à travers les axes
Nous allons maintenant explorer nos données en utilisant la totalité de notre modèle, ce qui implique de joindre la table de faits avec les tables dimensions.
En naviguant dans les axes en partant du niveau le plus fin, celui de la table de faits, et en remontant le long de l'axe d'analyse jusqu'au niveau le plus aggrégé, on rajoute des tables dans les requêtes, mais Oracle arrive toujours à les ré-écrire. En effet, vu que nos VM sont basées sur les champs de la table F_SALE, Oracle sait qu'il arrivera toujours à ré-écrire les requêtes en utilisant la logique suivante : rechercher une vue matérialisée utilisable dans les ré-écritures de requêtes (query rewrite enable) qui contienne tous les éléments dont la requête a besoin.
Ainsi, même en rajoutant plusieurs tables de dimensions normalisées, Oracle n'a aucun problème à ré-écrire correctement la requête : il détermine la VM à utiliser en fonction des dimensions utilisées puis il la joint aux tables de dimensions, voire à la hierarchie de tables de dimensions, et finalement procède au groupement. Oracle est aussi à l'aise pour grouper les données sur des identifiant (le code du vendeur ou du pays par exemple) que sur des attributs liés à ces identifiants (le nom du vendeur ou du pays par exemple).
IV. A venir :
- L'utilisation des dimensions
- Utiliser ces techniques à travers du reporting sexy (Business Objects)
- Aller plus loin :
- Les Materialized View Log et l'option refresh on commit
- Les vues matérialisées sur ROWID
- L'option compress
- Les Aggregate_aware de BO


Copyright © 2009 Nicolas Stefaniuk.
Aucune reproduction, même partielle, ne peut être faite
de ce site ni de l'ensemble de son contenu : textes, documents, images, etc.
sans l'autorisation expresse de l'auteur. Sinon vous encourez selon la loi jusqu'à
trois ans de prison et jusqu'à 300 000 € de dommages et intérêts.